

The Geometric Foundations of Machine Learning: A Deep Dive into Vector Operations and the Dot Product
In the rapidly evolving landscape of artificial intelligence and data science, the ability to process vast amounts of information rests upon a surprisingly elegant mathematical foundation: linear algebra. At the heart of this foundation lies the dot product, a fundamental operation that enables everything from the recommendation algorithms on Netflix to the complex linguistic processing of Large Language Models (LLMs) like ChatGPT. Understanding the dot product, however, requires more than just memorizing an algebraic formula; it demands a robust grasp of geometric principles, including unit vectors, scalar projections, and vector projections. This analysis explores these essential components, tracing their mathematical roots and their critical role in modern computational theory.
The dot product serves as a bridge between the abstract world of multi-dimensional coordinates and the intuitive world of physical geometry. While many students approach the subject through the lens of pure calculation, industry experts argue that a geometric intuition is what separates a proficient machine learning engineer from a mere practitioner. By decomposing vectors into their constituent parts—magnitude and direction—researchers can better understand how algorithms perceive "similarity" between different data points, a concept that is central to the functioning of modern AI.

The Unit Vector: Separating Magnitude from Direction
The first pillar of vector geometry is the concept of the unit vector. In any n-dimensional space, a vector is characterized by two primary attributes: how long it is (magnitude) and where it points (direction). Mathematically, a vector is designated as a unit vector if its magnitude is exactly one. This status is denoted by the symbol $|vecv| = 1$.
For any non-zero vector, the process of "normalization" allows mathematicians to isolate the direction of the vector while discarding its specific length. This is achieved by scaling the vector by the reciprocal of its magnitude. The resulting normalized vector, often written as $hatv$, represents the pure direction of the original vector $vecv$. This operation is foundational to data preprocessing in machine learning. When training a neural network, data scientists often normalize input features to ensure that variables with larger numerical scales do not disproportionately influence the model’s learning process. By treating every data point as a unit vector, the model can focus on the relationships and angles between features rather than their raw values.
This separation of "how much" from "which way" allows for a clearer visualization of vector space. In a two-dimensional plane, all possible unit vectors lie on the "unit circle"—a circle with a radius of one centered at the origin. Any unit vector forming an angle $theta$ with the x-axis can be described by the coordinates $(cos theta, sin theta)$. This relationship provides the first hint of the deep connection between the dot product and trigonometry.

Measuring Similarity Through Geometric Persuasion
The most immediate application of unit vectors is the measurement of similarity. When two unit vectors point in the exact same direction, they are considered perfectly similar. If they are perpendicular, they share no directional alignment. If they point in opposite directions, they are perfectly dissimilar.
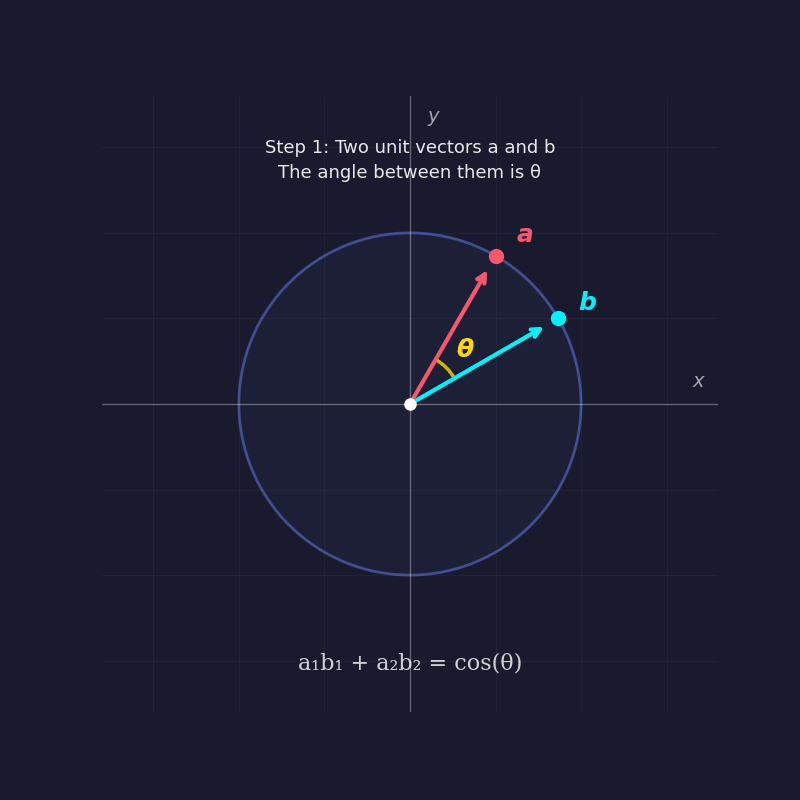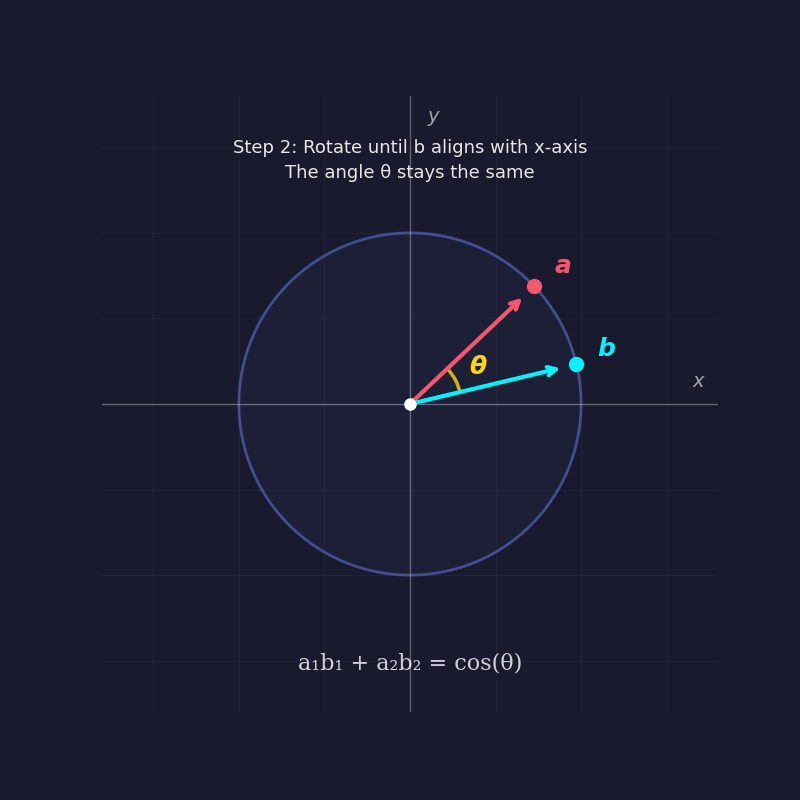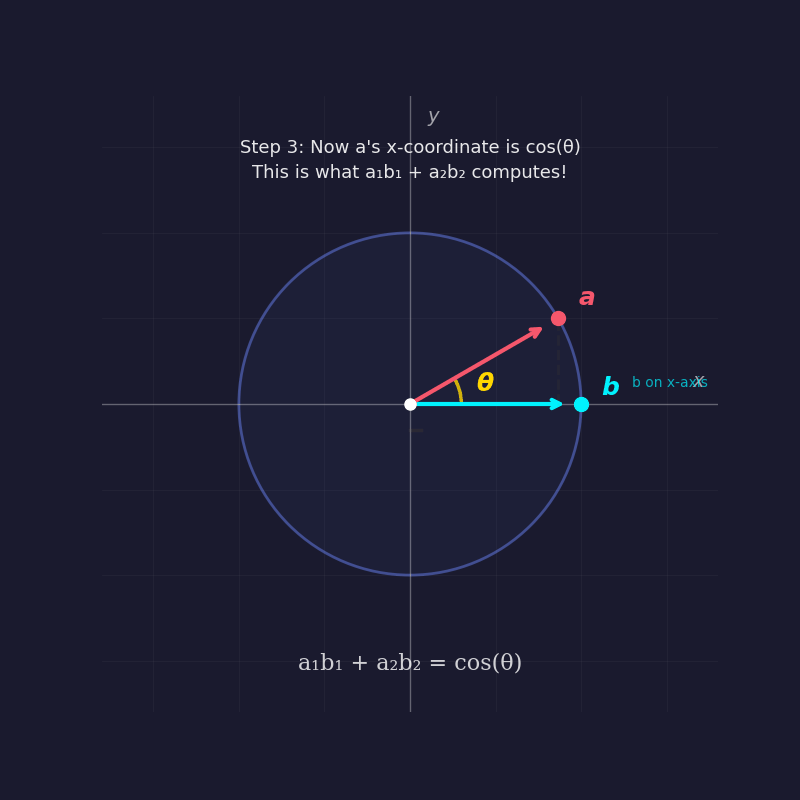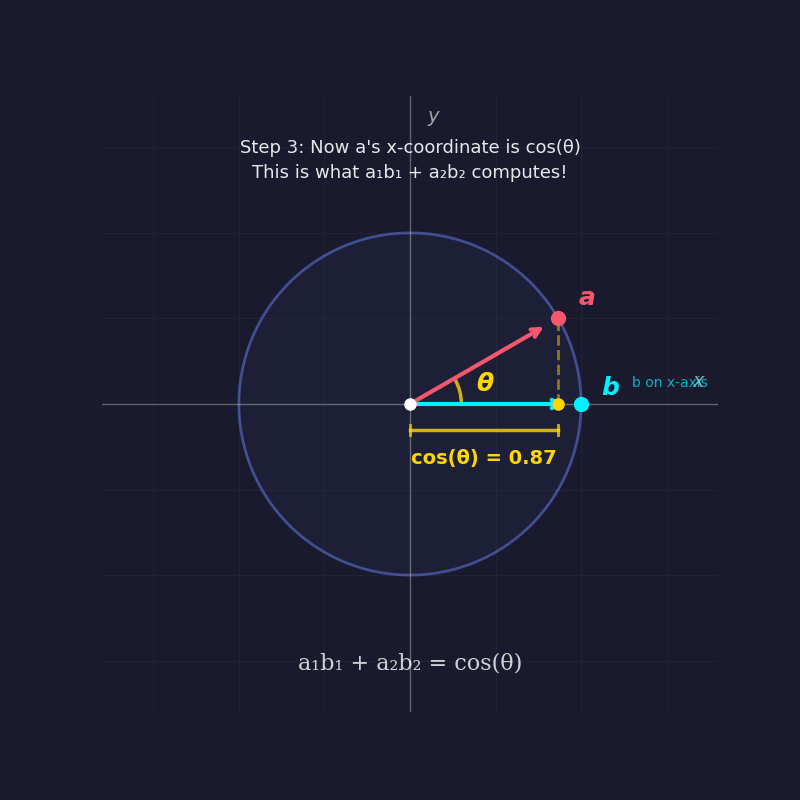
To prove why the dot product of two unit vectors equals the cosine of the angle between them, mathematicians often employ the "rotation trick." By rotating the entire coordinate system until one vector lies flat along the x-axis, the complexity of the problem is reduced without changing the underlying geometry. In this new orientation, one vector has coordinates $(1, 0)$, while the other, at an angle $theta$, has coordinates $(cos theta, sin theta)$. By multiplying the corresponding components and summing them—the very definition of a dot product—the result is $(cos theta times 1) + (sin theta times 0) = cos theta$.
This result is not limited to two dimensions. Because any two vectors, regardless of the dimensionality of the space they inhabit, define a single flat plane, this 2D proof remains valid for high-dimensional data, such as the 1,536-dimensional embeddings used in modern natural language processing.
Scalar Projection: The Intuition of the Shadow
If the unit vector represents direction, scalar projection represents the degree of alignment. The fundamental question scalar projection answers is: "How much of vector A lies along the direction of vector B?"
The most effective way to visualize this is through the "shadow analogy." Imagine a vector $veca$ held at an angle above a line representing the direction of vector $vecb$. If a light source shines directly down, perpendicular to the direction of $vecb$, the length of the shadow cast by $veca$ onto the line of $vecb$ is the scalar projection. This value is a single number (a scalar), which can be positive, zero, or negative depending on whether the vectors point generally in the same direction, are perpendicular, or point in opposite directions.
The formula for this "shadow length" is derived from basic trigonometry within a right-angled triangle, resulting in $|veca| cos theta$. In the context of the dot product, this can be expressed as $veca cdot hatb$, where $hatb$ is the unit vector of $vecb$. Essentially, the unit vector acts as a directional filter, extracting only the component of $veca$ that is relevant to the direction of $vecb$.

Vector Projection: Finding the Closest Point
While scalar projection provides a magnitude, vector projection provides a location. It answers the question: "Where exactly on the line of vector B is the point closest to the tip of vector A?"
To understand this, consider the "trail analogy." Imagine two hiking trails, A and B, diverging from a single starting point. If a hiker is restricted to walking only on Trail B but wishes to be as close as possible to a friend at the end of Trail A, they must stop at the point where a line drawn to their friend forms a 90-degree angle with Trail B. The vector starting at the origin and ending at this stopping point is the vector projection of A onto B.
The vector projection is calculated by taking the scalar projection (the distance walked) and multiplying it by the unit vector of B (the direction of the trail). This results in a new vector that is perfectly aligned with B but whose length is determined by the "shadow" of A. This concept is vital in algorithms like Principal Component Analysis (PCA), which seeks to project complex data onto lower-dimensional axes while preserving as much information as possible.

Historical Timeline and Computational Evolution
The development of these concepts follows a clear historical trajectory that mirrors the evolution of mathematical physics and computer science:
- 1840s – 1880s: Mathematicians such as Hermann Grassmann and William Rowan Hamilton began exploring "multilinear algebra." However, it was Josiah Willard Gibbs and Oliver Heaviside who formalized vector analysis in the 1880s, introducing the dot product as we know it today to simplify electromagnetic equations.
- 1950s – 1960s: The dawn of AI. Early neural models, like Frank Rosenblatt’s Perceptron, began using the dot product to calculate weighted sums of inputs, mimicking the way biological neurons integrate signals.
- 2012 – Present: The "Deep Learning Revolution." The realization that Graphics Processing Units (GPUs) are exceptionally efficient at performing massive parallel dot product operations allowed for the training of modern neural networks. A single "forward pass" in a modern LLM involves trillions of these calculations.
Industry Implications: The Rise of Vector Databases
The practical implications of these geometric foundations are immense. In the current tech economy, "Vector Databases" have emerged as a billion-dollar sub-sector. Companies like Pinecone, Weaviate, and Milvus provide specialized infrastructure designed to perform "nearest neighbor" searches. These searches rely entirely on calculating the dot product (or its cousin, cosine similarity) between a user’s query and millions of stored data points.
When a user types a query into a search engine, the system converts that text into a high-dimensional vector. It then uses the dot product to find which stored vectors (representing documents or images) have the highest "scalar projection" onto the query vector. Without the computational efficiency of the dot product and the geometric clarity of projections, modern digital life—from personalized shopping to AI-driven research—would be impossible.

Fact-Based Analysis: Why Geometric Intuition Matters
Data from computational benchmarks shows that the dot product is one of the most optimized operations in computer science. Modern CPUs and GPUs use specialized instruction sets, such as AVX-512 or Tensor Cores, to execute these operations at speeds exceeding trillions of floating-point operations per second (TFLOPS).
However, the "black box" nature of AI often masks the underlying geometry. Analysts suggest that as AI models become more complex, the industry is seeing a return to "first principles." Understanding vector projection, for instance, is essential for "AI Safety" and "Interpretability" research. By projecting the internal states of a neural network onto specific "concept vectors," researchers can begin to decode what an AI is "thinking" or identify where its logic might be biased.
Conclusion and Future Outlook
The dot product is more than a line in a textbook; it is the mathematical heartbeat of the information age. By mastering unit vectors and the nuances of projection, one gains a window into how machines perceive the world. This first exploration of geometric foundations sets the stage for deeper inquiries into cosine similarity and the practical applications of these tools in recommendation systems and natural language processing. As we move toward more sophisticated artificial general intelligence, these century-old geometric truths will remain the essential coordinates guiding our progress.


