

Agentic AI in Ecological Modelling: A Rigorous Test Reveals Promise and Pitfalls
A comprehensive study published in the esteemed journal Fish and Fisheries has subjected agentic Artificial Intelligence (AI) tools, such as Claude Code, to rigorous testing in the domain of ecological modelling. The research, originating from Seascapemodels and contributed to R-bloggers, aimed to ascertain the reliability of these advanced AI systems in performing complex fisheries tasks, including writing and executing code, autonomously correcting errors, and generating formatted reports complete with visualizations. The findings indicate that while agentic AI presents genuine utility for ecological modellers, its effective application hinges on a deep understanding of the analytical processes and a vigilant approach to verifying AI-generated outputs.
The investigation involved a systematic evaluation of four distinct AI models, each tasked with three specific fisheries modelling challenges. These challenges were deliberately chosen to encompass both common ecological modelling practices and more specialized fisheries analyses, pushing the boundaries of what might be expected from AI models potentially lacking extensive exposure to such niche datasets in their training. The rigorous methodology included ten independent runs for each task per AI model, with all outputs meticulously scored against a predefined rubric assessing accuracy, code quality, and report quality. This multi-faceted approach was designed to capture not only the peak performance of the AI agents but also their consistency and reliability across repeated trials, acknowledging the inherent randomness often present in Large Language Model (LLM) responses.
Methodology: A Deep Dive into AI Performance
The research team employed Roo Code, an open-source and highly customizable agentic AI integrated within the VS Code environment, as their primary testing platform. Unlike conventional chatbots, Roo Code possesses the capability to write, execute, and debug code autonomously, iterating through solutions based on error feedback. The selection of Roo Code underscores a commitment to transparency and the potential for future adaptation and refinement of AI-driven modelling workflows.
The three core tasks presented to the AI models were:
- Generalized Linear Model (GLM) of Fish Abundance and Coral Habitat: This task represents a foundational ecological modelling problem, widely used for analyzing relationships between environmental variables and species distribution or abundance.
- Fitting a von Bertalanffy Growth Curve: This is a standard method in fisheries science for describing the growth of individual fish over time, a critical parameter for stock assessment and management.
- Yield Per Recruit Analysis: This specialized fisheries analysis aims to determine the optimal fishing strategy by evaluating the potential yield obtainable from a cohort of fish subjected to different fishing pressures and natural mortality rates throughout their life.
The choice of these specialized tasks was strategic. By selecting analyses that are prevalent in ecological science but perhaps less common in general LLM training datasets, the researchers sought to uncover potential limitations or biases in the AI’s understanding and application of domain-specific methodologies.
To account for the probabilistic nature of LLM outputs, each task was executed ten times independently. This approach allowed the researchers to assess the consistency of the AI’s performance, a crucial factor for any scientific application where reproducibility and reliability are paramount. The scoring rubric was designed to be comprehensive, evaluating:
- Accuracy: How closely the AI’s results matched known benchmarks or expected outcomes.
- Code Quality: The efficiency, readability, and robustness of the generated R code.
- Report Quality: The clarity, completeness, and professional presentation of the accompanying reports and visualizations.
The study evaluated four LLMs: Claude Sonnet 4.0 and its subsequent iteration, Sonnet 4.5, which became available during the review process and was subsequently incorporated into the analysis. Additionally, the open-weight model Kimi K2 and its specialized "exacto" variant were tested. The inclusion of the "exacto" variant of Kimi K2, which intelligently routes requests to the most performant providers on platforms like OpenRouter, provided valuable insights into the impact of underlying computational infrastructure on the performance of open-weight models. The findings suggested that "exacto" significantly outperformed standard K2 requests, highlighting the critical role of hardware quality and optimized deployment for open-weight LLMs.
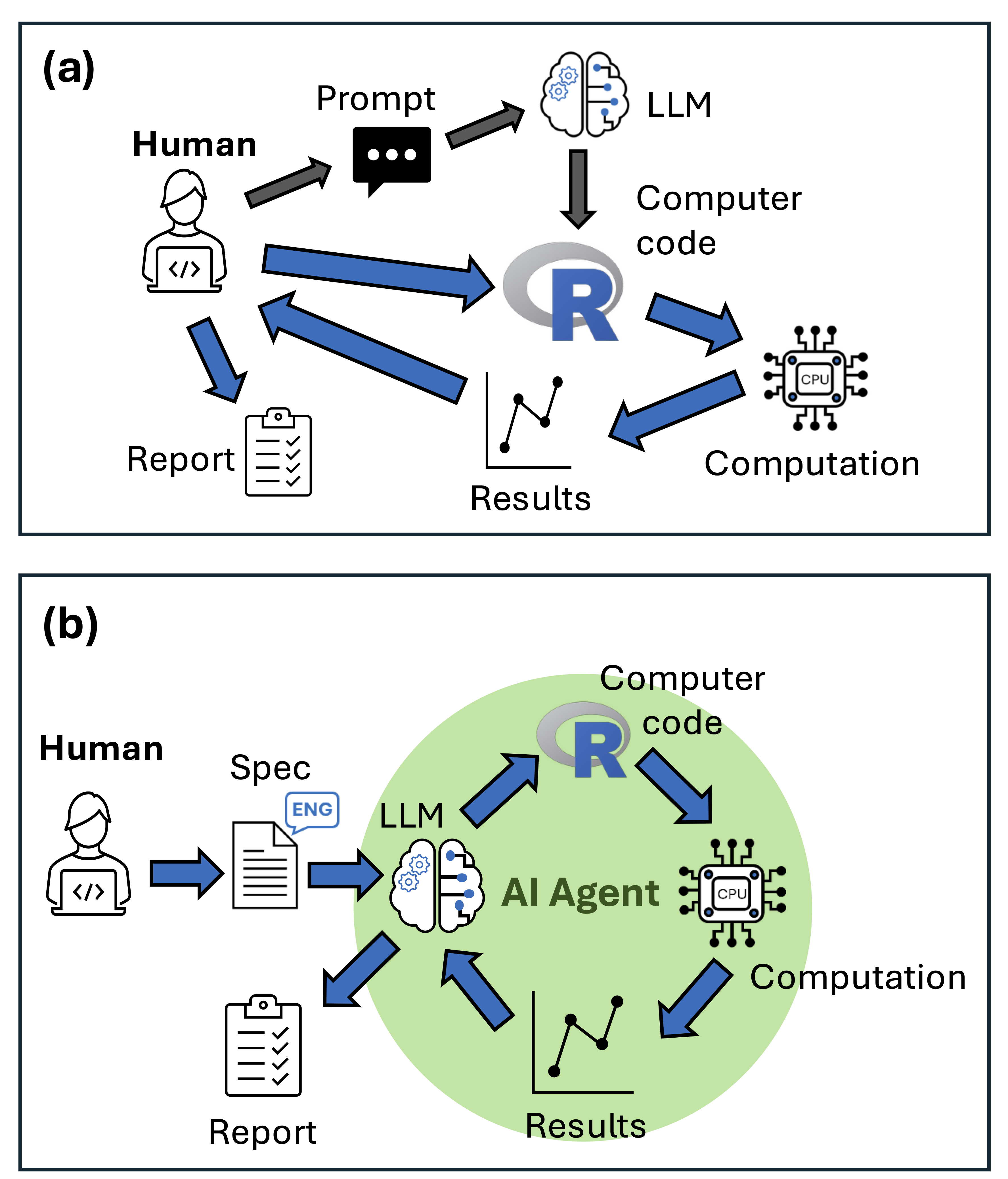
Key Insights: Navigating the Agentic AI Landscape
The research yielded several critical lessons for scientists seeking to leverage agentic AI in ecological modelling. Foremost among these is the imperative to develop exceptionally detailed specification sheets. These documents, often spanning multiple pages, must comprehensively outline analytical objectives, data structures, recommended R functions and packages, desired output formats, and file naming conventions. While time-consuming, the meticulous construction of these sheets serves a dual purpose: it clarifies the researcher’s own understanding of the analysis and provides the AI with unambiguous guidance. An example of such a detailed specification sheet for a GLM test case is publicly available on GitHub, offering a practical template for other researchers.
A recurring theme in the study was the tendency for AI agents to default to the most common methodologies encountered in their training data, which may not always align with the specific requirements of a research question. The researchers emphasized the necessity of explicitly specifying desired algorithms. For instance, if bootstrapped confidence intervals using the boot package are required, this must be clearly articulated. Even with explicit instructions, the AI’s adherence can be inconsistent. The study noted instances where Claude models repeatedly applied natural mortality to the first age class in the yield per recruit model, despite direct instructions to the contrary. Such subtle, yet significant, methodological deviations can lead to inaccuracies in critical outputs like catch estimates, underscoring the indispensable role of expert human oversight.
The variability observed in accuracy scores across multiple runs highlighted another crucial strategy: running replicates and rigorously comparing outputs. The AI’s performance could range from near-perfect parameter estimation to systematic errors in specific analytical components. By executing multiple agents and comparing their results, researchers can identify the most robust and accurate solutions.
Furthermore, the study identified a critical blind spot in current agentic AI: their limited capacity for self-directed conceptual validation. For example, none of the AI agents automatically checked for collinearity among predictors in the GLM analysis, a standard and vital step in regression modeling. While the GLMs themselves ran without syntax errors and produced seemingly coherent results, the underlying data exhibited strong collinearity, a flaw that could significantly distort interpretations. This observation strongly suggests that while AI agents excel at code generation and execution, their conceptual implementation of analytical principles can be incomplete, misleading, or logically flawed.
The Peril of Plausible but Flawed Outputs
Perhaps the most significant concern raised by the study is the potential for agentic AI to generate professionally formatted reports that contain subtle yet critical logical errors. Coding syntax errors are readily detectable, but methodological shortcuts or misapplications embedded within otherwise polished output can easily go unnoticed by researchers lacking a deep, a priori understanding of the specific analytical techniques.
This presents a genuine risk, particularly for early-career researchers who may lack the foundational knowledge to critically evaluate AI-generated analyses. Even experienced scientists could fall prey to overconfidence, potentially overlooking flaws in outputs that appear technically sound and visually appealing. The implications of such undetected errors can be far-reaching, potentially influencing scientific conclusions and subsequent real-world applications. The study draws a parallel to documented instances where human errors in ecological modelling have led to significant impacts on decisions regarding invasive species management, underscoring the profound consequences of flawed scientific analysis.
Future Directions and Recommendations
Despite these challenges, the study concludes that agentic AI offers substantial efficiency gains for scientists with a strong quantitative background. The researchers have made their specification sheets and rubrics available in the supplemental materials of their publication, encouraging adaptation by other research groups. All associated code is also publicly accessible on GitHub, enabling the scientific community to conduct their own tests and further explore the capabilities and limitations of these evolving AI tools.
The open-access publication in Fish and Fisheries (Brown et al. 2026) serves as a foundational contribution to the responsible integration of AI in ecological research. The findings advocate for a collaborative approach, where AI acts as a powerful assistant, augmenting human expertise rather than replacing it. The ongoing development of agentic AI promises further advancements, but a commitment to rigorous testing, transparent reporting, and expert human supervision will remain paramount to ensuring the integrity and reliability of scientific endeavors. As AI continues to permeate scientific workflows, the lessons learned from this study offer a critical roadmap for navigating its potential and mitigating its inherent risks.

